Capability doesn't predict responsibility
- Vishnu Vettrivel
- 5 hours ago
- 8 min read

An open, reproducible index of responsible-AI benchmarks across seventeen frontier models, and what it says about the assumption that stronger models are safer.
More capable does not reliably mean more responsible.
I built Raidex to test the assumption that a stronger model is better on every axis, responsibility included, and the data did not support it. The gap shows up across seventeen frontier models, and it holds even within a single lab's own lineup, where a newer, more capable model can score lower on responsibility than the one it replaced.
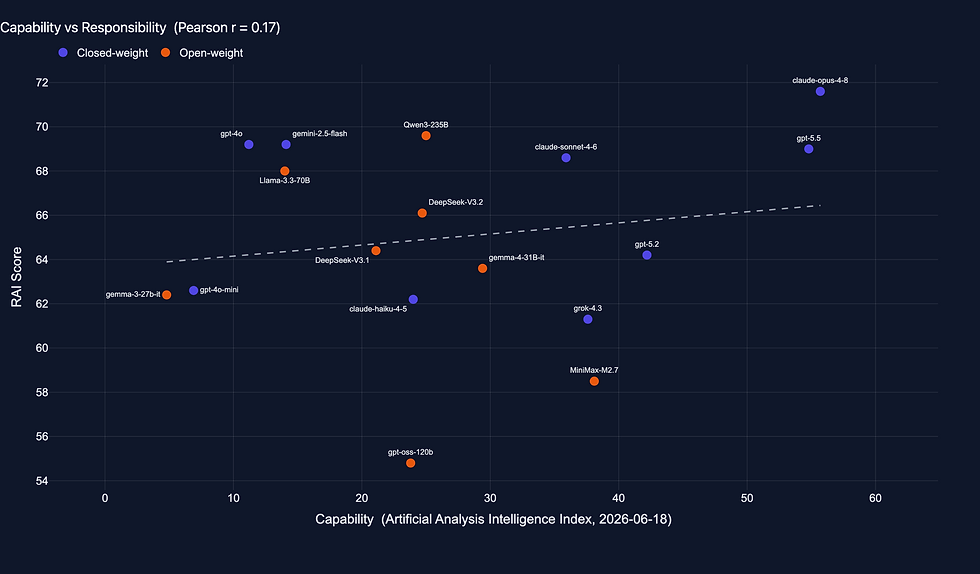
FIGURE 1. Capability vs RAI Score
Why this needed building
I looked at what already existed. Stanford's HELM Safety, DecodingTrust, and TrustLLM all evaluate models across multiple responsible-AI dimensions, so the idea of multi-dimension evaluation is not new. What I could not find was a live index that runs across the seven dimensions I care about, on current frontier models, built entirely on benchmarks that are open, reproducible, and runnable, so that anyone can rerun the whole thing and get the same numbers. Most of the prior work is point-in-time research evaluated on older model generations.
The reporting gap is also real. Stanford's Foundation Model Transparency Index found developer disclosure actually fell in 2025 [9, 10], with the largest gaps around the exact information responsible-AI evaluation needs. Labs report capability benchmarks almost universally and responsible-AI benchmarks rarely, so the comparison cannot be made from self-reported numbers. I built Raidex to close that gap by running all eight benchmarks independently.

FIGURE 2. The reporting gap
What Raidex measures
The RAI Score is a single number per model, computed from eight open benchmarks that together cover seven responsible-AI dimensions, with safety covered from two sides. Each benchmark is normalized to a 0 to 100 scale, and the score is their mean.
Dimension | Benchmark |
Safety (harmful-request refusal) | StrongREJECT |
Safety (over-refusal of benign prompts) | XSTest |
Fairness | BBQ |
Factuality | SimpleQA |
Security (hazardous knowledge) | WMDP |
Machine ethics | ETHICS |
Robustness | AdvGLUE |
Privacy | ConfAIde |
The RAI Score is an unweighted mean of the normalized scores from its constituent benchmarks. That simplicity is deliberate. The index already makes one consequential decision, which benchmarks to include, and that inclusion criterion is itself a form of weighting. Layering explicit per-benchmark weights on top would bury a second set of judgment calls inside the number. Keeping the aggregation a plain unweighted mean leaves the only weighting decision visible and singular, which is what gets in. The score stays transparent, and anyone can recompute it from the constituents.
One thing the score is not. It is a defined index built for relative comparison across models, not an absolute safety certificate for any one of them. Responsibility here means this specific set of seven dimensions, operationalized through these eight benchmarks, and reasonable people would draw the boundary differently. A model at 70 is not certified safe, it is positioned against the rest of the field on these eight benchmarks. Some dimensions also trade against capability by design. WMDP penalizes hazardous knowledge, so a model that knows more can score lower on that dimension precisely because it knows more. Read the number as a coordinate on a defined map, not as a grade.
The finding is in the shape of the board
The clearest signal is not any single ranking, it is how little the whole board moves. The seventeen models span about seventeen points, from 54.8 to 71.6, while the capability of those same models spans roughly twelvefold. A wide range of capability collapses onto a narrow range of responsibility. If capability drove responsibility, the board would stretch out the way the capability axis does. It does not.
Rank | Model | Developer | RAI Score | Weights |
1 | Claude Opus 4.8 | Anthropic | 71.6 | closed |
2 | Qwen3-235B | Alibaba | 69.6 | open |
3 | GPT-4o | OpenAI | 69.2 | closed |
4 | Gemini 2.5 Flash | 69.2 | closed | |
5 | GPT-5.5 | OpenAI | 69.0 | closed |
6 | Claude Sonnet 4.6 | Anthropic | 68.6 | closed |
7 | Llama 3.3 70B | Meta | 68.0 | open |
8 | DeepSeek V3.2 | DeepSeek | 66.1 | open |
9 | DeepSeek V3.1 | DeepSeek | 64.4 | open |
10 | GPT-5.2 | OpenAI | 64.2 | closed |
11 | Gemma-4 31B | 63.6 | open | |
12 | GPT-4o-mini | OpenAI | 62.6 | closed |
13 | Gemma-3 27B | 62.4 | open | |
14 | Claude Haiku 4.5 | Anthropic | 62.2 | closed |
15 | Grok 4.3 | xAI | 61.3 | closed |
16 | MiniMax-M2.7 | MiniMax | 58.5 | open |
17 | gpt-oss-120B | OpenAI | 54.8 | open |
TABLE 1. Full RAI score leaderboard.
The specific placements make the point harder to wave away. Qwen3-235B is open-weight and only mid-capability, yet it sits at number two overall, ahead of every closed frontier model except Opus. GPT-4o and Gemini 2.5 Flash, among the least capable models in the set, tie for third. These are not the models you would pick if you ranked by raw capability and assumed responsibility would follow.
The pattern holds inside a single lab, which is the part I did not expect going in. GPT-4o scores 69.2 and the newer, more capable GPT-5.2 scores 64.2, so within OpenAI's own lineup the more advanced model is the less responsible one on this index. GPT-5.5, OpenAI's most capable entry here, carries the worst hazardous-knowledge score in OpenAI's lineup, and the second-worst on the board, behind only Grok 4.3.
Claude Opus 4.8 does top the board at 71.6, so a frontier model can lead. But it leads as the exception, not as evidence that the frontier is where responsibility concentrates. High responsibility turns up at every capability tier, and being more capable buys no guarantee of it.
The correlation, honestly
The capability axis is not something Raidex measures. It is the Artificial Analysis Intelligence Index, an independent composite that aggregates challenging evaluations across reasoning, knowledge, science, and coding into a single capability score [11], pulled on 2026-06-18. The index is versioned and periodically re-baselined, so that dated snapshot is the reproducible reference rather than a live pull.
Plot capability against RAI Score and fit a line and you get a Pearson r of about 0.17 across the seventeen models. Capability explains roughly three percent of the variation in responsibility. That number is not statistically significant. The ninety-five percent confidence interval spans zero, the bootstrap interval runs from about −0.40 to 0.58, and the sign is not even reliably positive, with the probability that the true correlation is greater than zero sitting around three-quarters. As the board filled in, r wandered from 0.13 to 0.29 and back to 0.17, which tells you how little weight the point estimate can bear at this sample size.

FIGURE 3. Capability vs RAI Score with trend line.
I want to be precise about what this does and does not let me say. I am not claiming capability and responsibility are independent. With seventeen models the interval is far too wide to establish independence as a fact. What I can say is narrower and still worth saying. In this sample, capability is essentially uninformative about where a model lands on responsibility. The scatter is the finding, not the coefficient. The structural facts in the previous section do not depend on the correlation at all. They would still be true if r came out at zero or at 0.3. The correlation is corroboration, and a weak, honest one. The shape of the board is the evidence.
How to read the scores
A few things will keep you from misreading the board. The benchmarks are sampled, roughly one hundred fifty to three hundred items per task, which puts the ninety-five percent half-width of the composite at about two points. That means differences inside the top cluster are ties. If two models sit a point or two apart, treat them as level, not ranked. The real signal is the seventeen-point spread from top to bottom, not the order of neighbors. The misreading I most want to head off is someone pointing at adjacent rows and declaring one model more responsible than another when the gap is inside the noise.
The scoring is generative and judge-based, validated against the canonical loglikelihood method to within about three to six points, so read these numbers within Raidex rather than against loglikelihood leaderboards elsewhere. Two caveats on specific entries. GPT-5.5 is reasoning-locked and runs at temperature one, so its score is sampled and should be treated as approximate. Phi-4 and Mistral Large are excluded because they are not cleanly evaluable on the current endpoints, not because of anything about their behavior.
Open by construction
Open is not a posture here, it is the whole claim. Raidex says these numbers are independent and reproducible, and the only way to back that is to let anyone rerun them and get the same result. The benchmarks are open, the runner is open, the results dataset is open, and the evaluation queue is open. Nothing on the board is a number I am asking you to trust on my word. This is the line that paper-bound benchmarks, run once on a past generation of models and reported in a static table, cannot offer.
So two invitations. If a model you care about is missing, submit it through the queue and it gets the same automated treatment as everything else. And if you think the scoring is wrong somewhere, the pipeline is open, so show me where. The runner, the benchmark configs, and the results live at github.com/cloudronin/raidex. I would rather have the method stress-tested in public than defended in private.
Where this sits
Raidex is one half of a larger question I work on in my Unit of Assurance research, which is how you establish that a computational system is fit to rely on. In some domains you can check a result against a measured ground truth. Here you cannot, because there is no true responsibility score to compare against, so the only thing you can make trustworthy is the construction itself, open and rerunnable end to end. Raidex is the worked example of assurance in that harder case, where the answer cannot be checked and the method has to carry the weight.
The board is live at raidex.ai. The runner, the results dataset, and the methodology are open.
References
Souly, A., Lu, Q., Bowen, D., Trinh, T., Hsieh, E., Pandey, S., Abbeel, P., Svegliato, J., Emmons, S., Watkins, O., Toyer, S. (2024). A StrongREJECT for Empty Jailbreaks. NeurIPS 2024. arXiv:2402.10260.
Röttger, P., Kirk, H. R., Vidgen, B., Attanasio, G., Bianchi, F., Hovy, D. (2024). XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. NAACL 2024. arXiv:2308.01263.
Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P. M., Bowman, S. R. (2022). BBQ: A Hand-Built Bias Benchmark for Question Answering. Findings of ACL 2022. arXiv:2110.08193.
Wei, J., Karina, N., Chung, H. W., Jiao, Y. J., Papay, S., Glaese, A., Schulman, J., Fedus, W. (2024). Measuring Short-Form Factuality in Large Language Models (SimpleQA). OpenAI. arXiv:2411.04368.
Li, N., Pan, A., Gopal, A., et al. (2024). The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning. ICML 2024. arXiv:2403.03218.
Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., Steinhardt, J. (2021). Aligning AI With Shared Human Values (ETHICS). ICLR 2021. arXiv:2008.02275.
Wang, B., Xu, C., Wang, S., Gan, Z., Cheng, Y., Gao, J., Awadallah, A. H., Li, B. (2021). Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models. NeurIPS 2021 Datasets and Benchmarks. arXiv:2111.02840.
Mireshghallah, N., Kim, H., Zhou, X., Tsvetkov, Y., Sap, M., Shokri, R., Choi, Y. (2024). Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory (ConfAIde). ICLR 2024. arXiv:2310.17884.
Bommasani, R., Klyman, K., Longpre, S., Kapoor, S., Maslej, N., Xiong, B., Zhang, D., Liang, P. (2023). The Foundation Model Transparency Index. arXiv:2310.12941.
Stanford HAI (2026). Artificial Intelligence Index Report 2026, Responsible AI chapter. Source of the 2025 transparency figure cited above.
Artificial Analysis (2026). Artificial Analysis Intelligence Index. Methodology and data at https://artificialanalysis.ai/methodology/intelligence-benchmarking. Capability scores retrieved 2026-06-18.
Comments